机器学习初学者
机器学习入门简介
简介
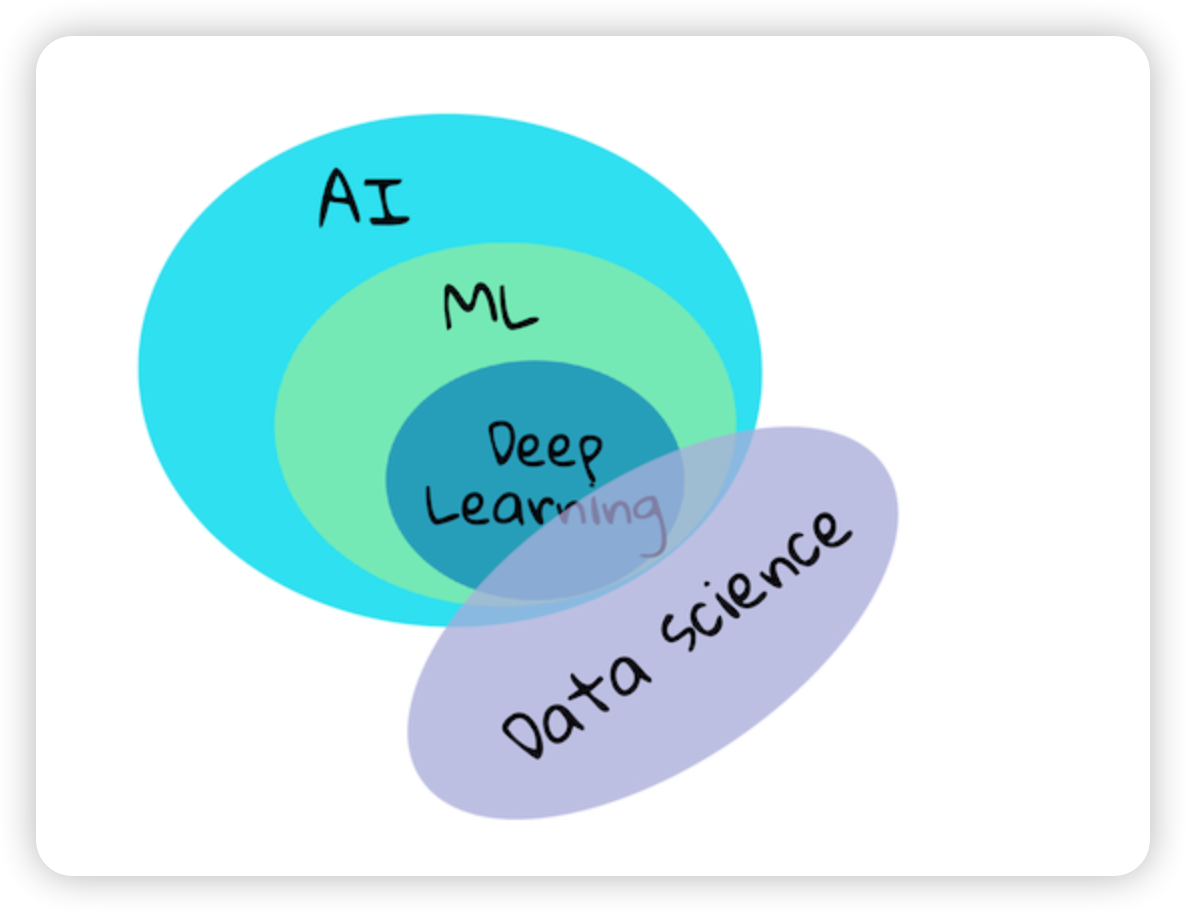
- 监督学习
- 分类(Classification)
- 回归(Regression)
- 无监督学习
- 聚类(Clustering)
- 降维(Dimensionality Reduction)
- 强化学习
机器学习的历史
机器学习的流程
- 收集整理数据----特征选择和特征提取
- 可视化数据、拆分数据集(训练集、测试集)
- 建立模型----训练模型、评估模型
- 参数调优
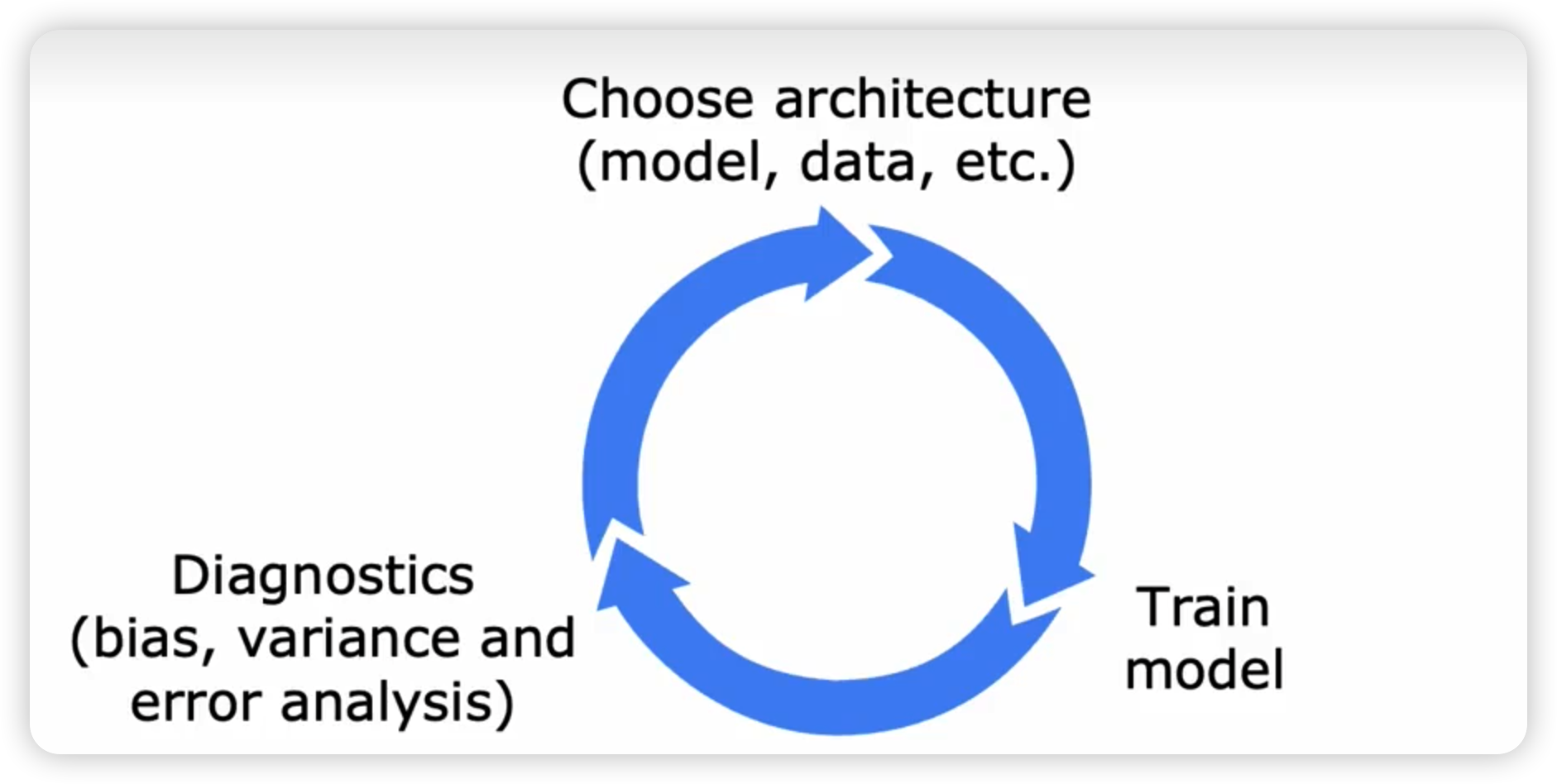
线性回归
模型和损失函数

梯度下降
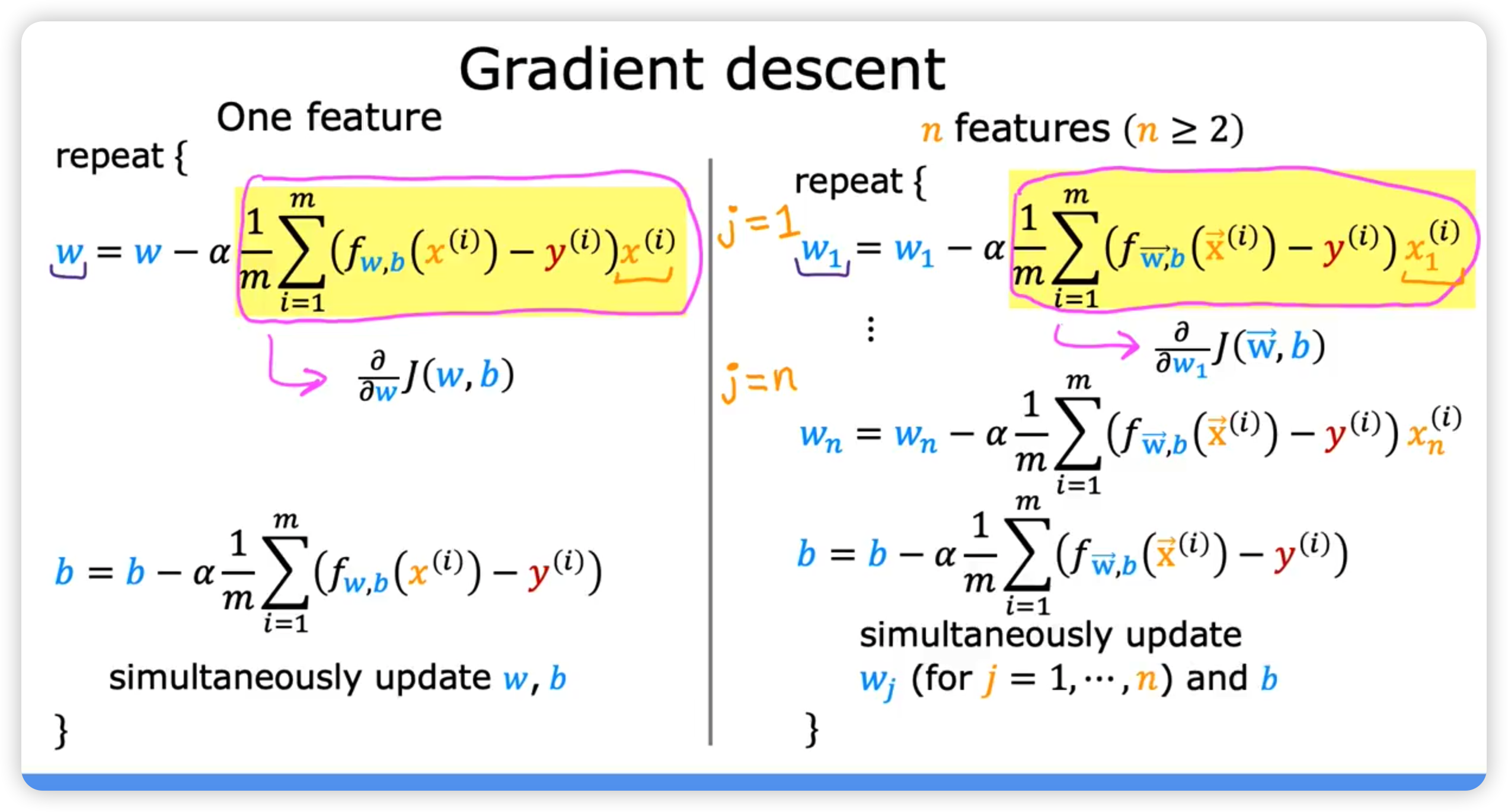
梯度下降法的矩阵方式描述(代码实现比较简洁)
批量梯度下降法(Batch Gradient Descent, BGD):梯度下降的每一步中,都用到了所有的训练样本
随机梯度下降法(Stochastic Gradient Descent, SGD):梯度下降的每一步中,用到了一个样本,在每一次计算后便更新参数,而不需要首先将所有的训练集求和
小批量梯度下降法(Mini-batch Gradient Descent, MBGD):梯度下降的每一步中,用到了一定批量(16、32、64、128)的训练样本
高阶优化方法
- Adam Algorithm
分类
Logistic 回归
Sigmoid function

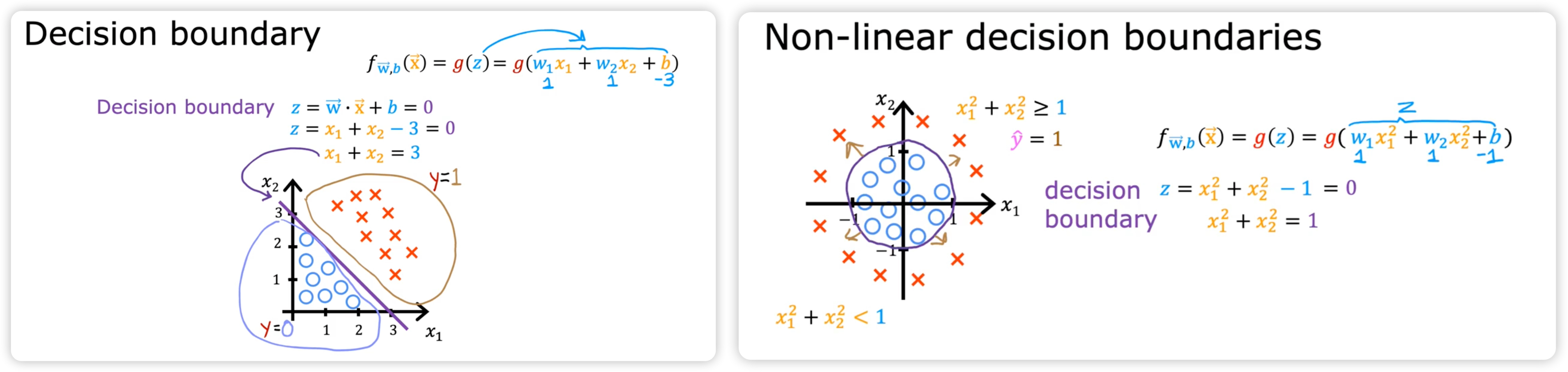
决策边界 decision boundary
损失函数 Loss Function


梯度下降

尽管梯度下降的方法在线性回归和 Logistic 回归上的表现形式一样;当是两者的函数的定义是不同的。
神经网络 Neural networks
感知机(前身)
神经网络的简介
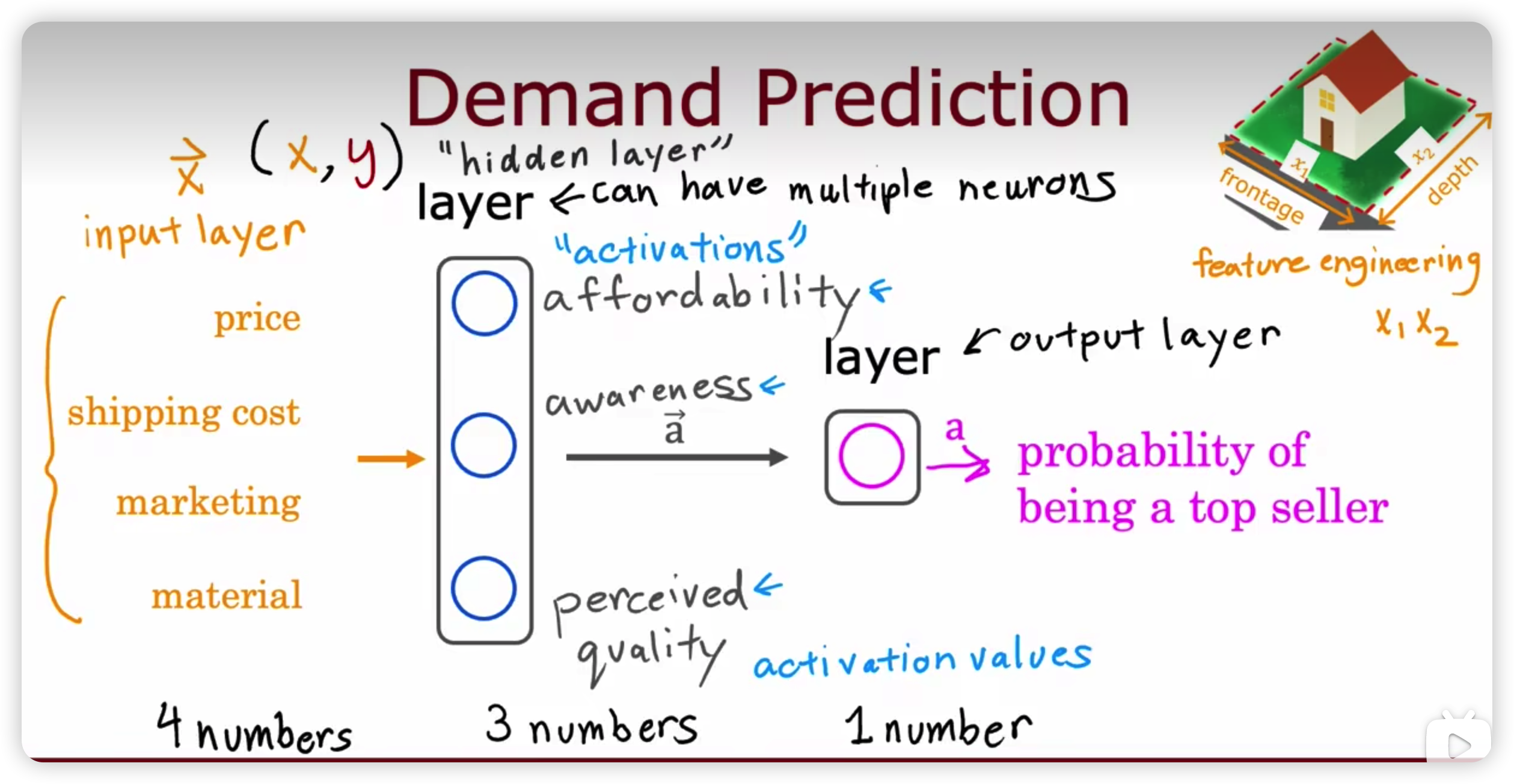
- 正向传播
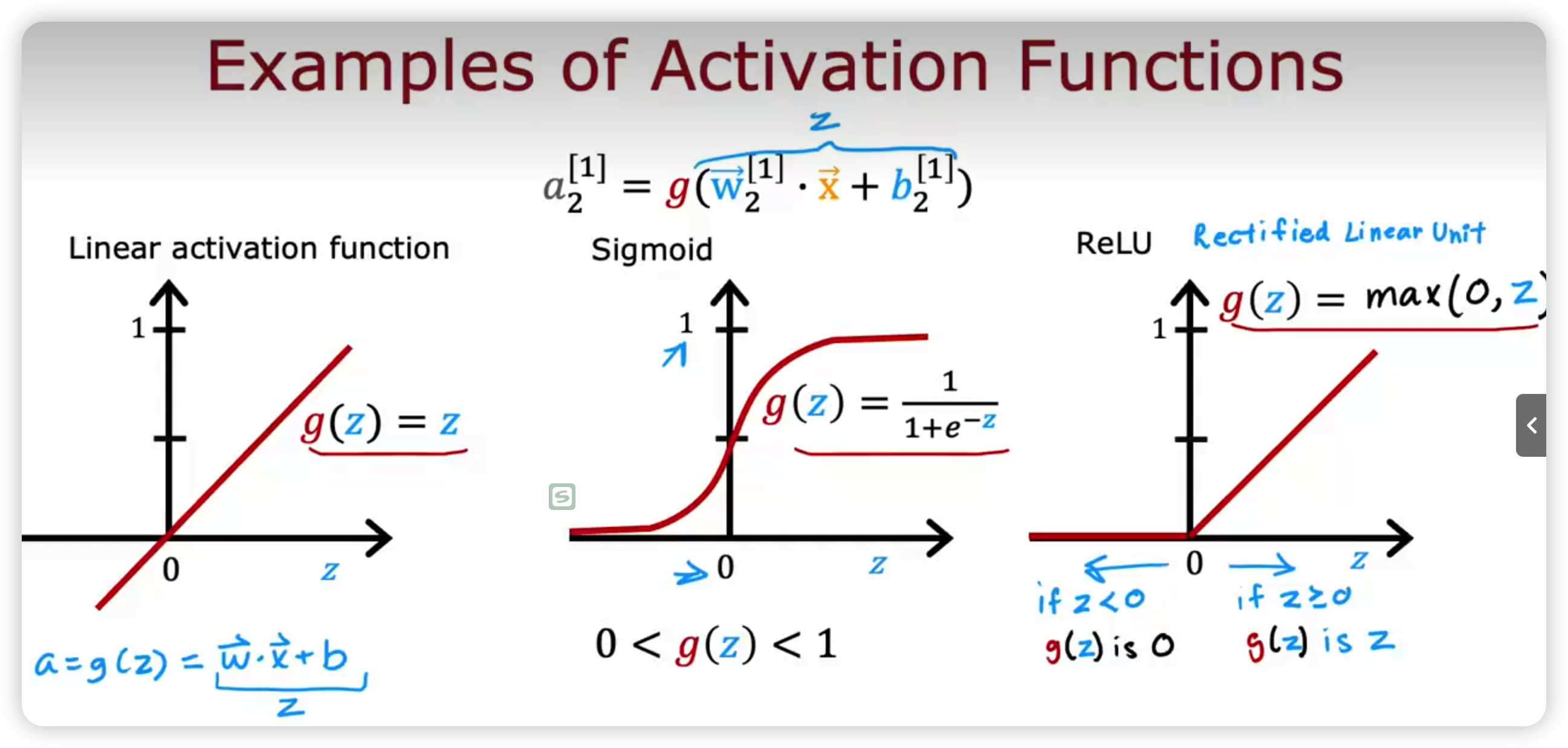
- 激活函数
- Softmax 函数
- 隐藏层
- 卷积层----仅计算部分输入
- 输出层
- 反向传播
如何提升算法的性能
- 划分训练集和测试集
- 交叉验证
- 建立表现基准
- 绘制学习曲线
决策树
- 决定在节点使用什么特征进行划分
- 停止划分的条件
- 剪枝???
- 回归树
- 集成学习--随机森林--bagging--bosting
聚类算法 K--means

tips
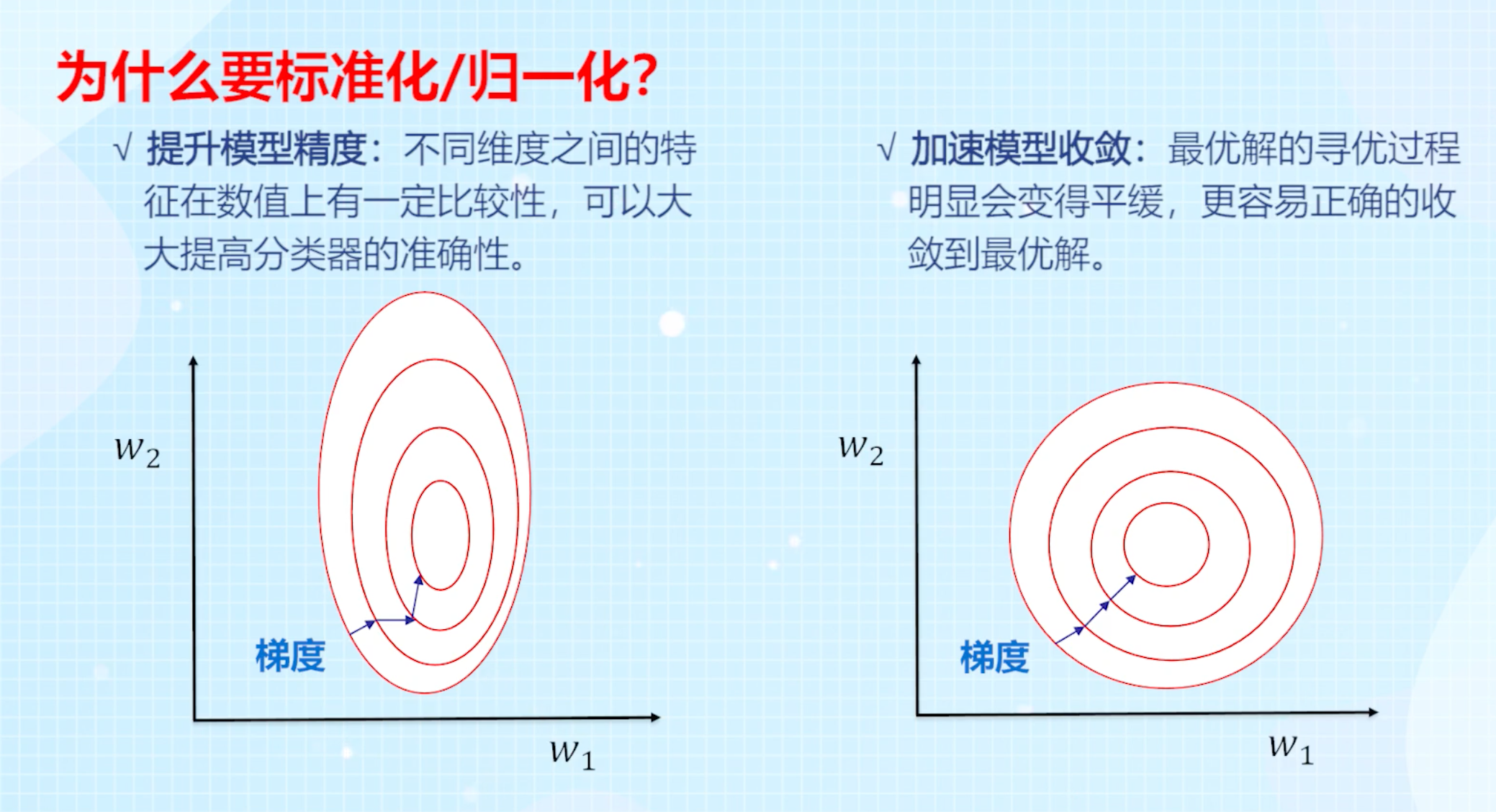
数据预处理
最大最小值归一化(min-max normalization):将数值范围缩放到 [0, 1] 区间里
均值归一化(mean normalization):将数值范围缩放到 [-1, 1] 区间里,且数据的均值变为0
标准化 / z值归一化(*s**tandardization /*** z-score *normalization**)*:将数值缩放到0附近,且数据的分布变为均值为0,标准差为1的标准正态分布(先减去均值来对特征进行 中心化 mean centering 处理,再除以标准差进行缩放)
- 通过绘制学习曲线来帮助判断梯度下降是否收敛--学习率的选择
过拟合 Overfitting
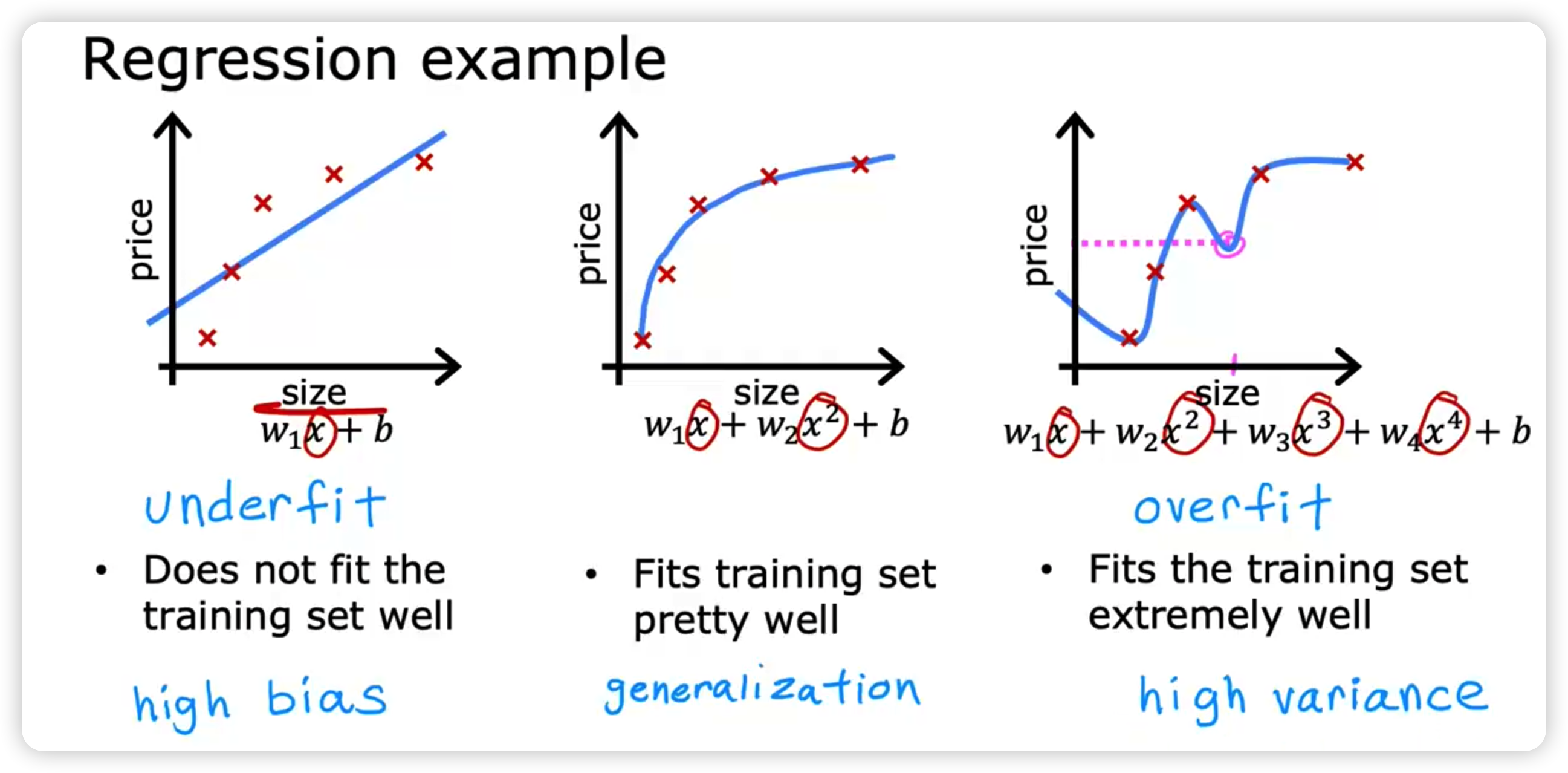
- Bias -- 模型在训练集上的误差
- Variance -- 训练集误差和测试集误差之间的差距
- 解决方法--过拟合

- 收集更多的训练数据
- 降维--减少使用的特征(feature)的数量--即挑选更有用的特征
- 正则化
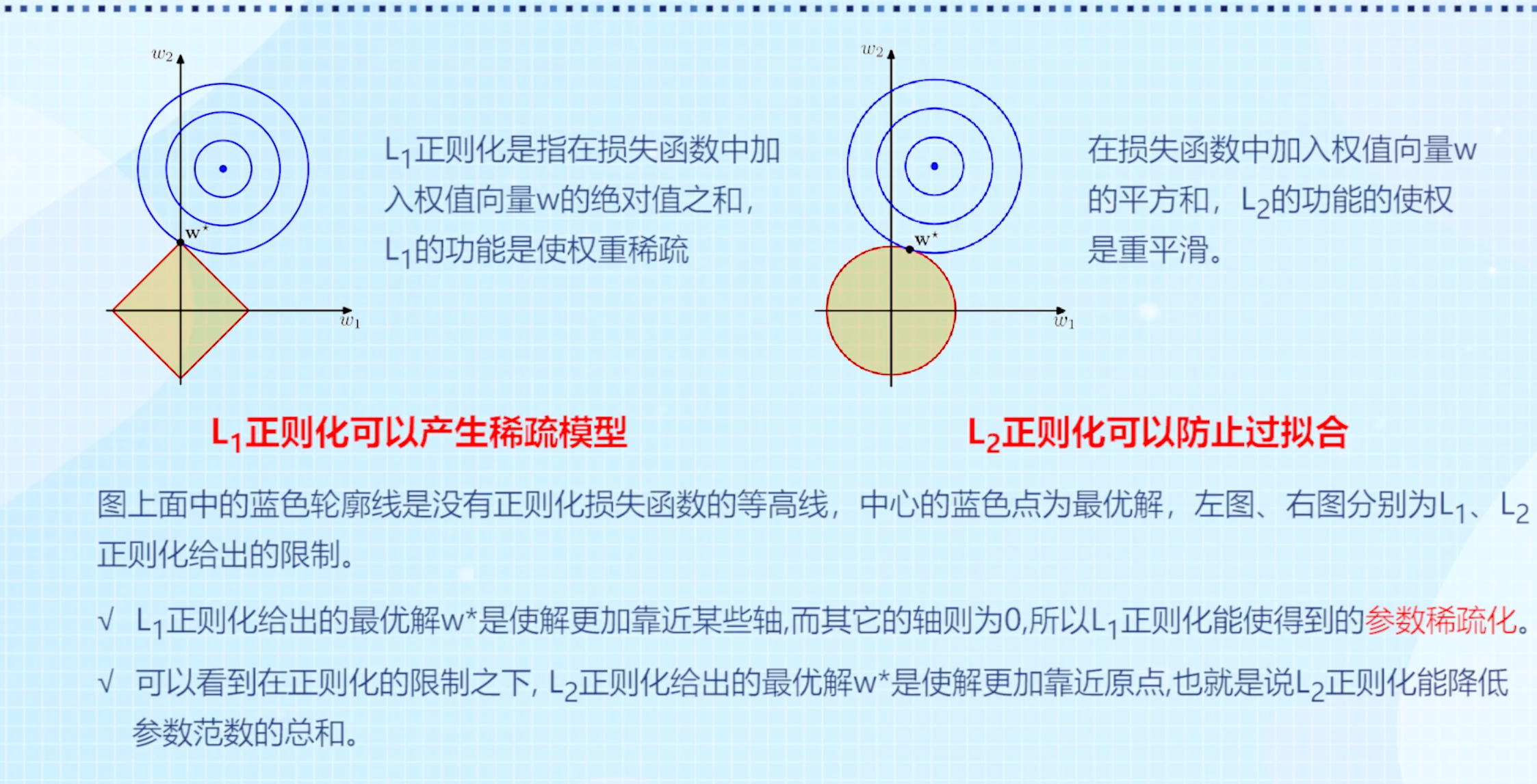
- 参考内容:https://lulaoshi.info/machine-learning/linear-model/regularization
- 简介
- 机器学习的历史
- 机器学习的流程
- 线性回归
- 梯度下降
- 梯度下降法的矩阵方式描述(代码实现比较简洁)
- 批量梯度下降法(Batch Gradient Descent, BGD):梯度下降的每一步中,都用到了所有的训练样本
- 随机梯度下降法(Stochastic Gradient Descent, SGD):梯度下降的每一步中,用到了一个样本,在每一次计算后便更新参数,而不需要首先将所有的训练集求和
- 小批量梯度下降法(Mini-batch Gradient Descent, MBGD):梯度下降的每一步中,用到了一定批量(16、32、64、128)的训练样本
- 高阶优化方法
- 分类
- Logistic 回归
- 神经网络 Neural networks
- 感知机(前身)
- 神经网络的简介
- 如何提升算法的性能
- 决策树
- 聚类算法 K--means
- tips